تجزیه و تحلیل داده بزرگ
در طول چند سال گذشته، سازمانها در بخشهای دولتی و خصوصی تصمیمات استراتژیکی برای تبدیل دادههای بزرگ به مزیت رقابتی ایجاد کردهاند. چالش استخراج از دادههای بزرگ به طرق مختلف، مشابه یک مشکل هوش تجاری از دادههای تجاری است.
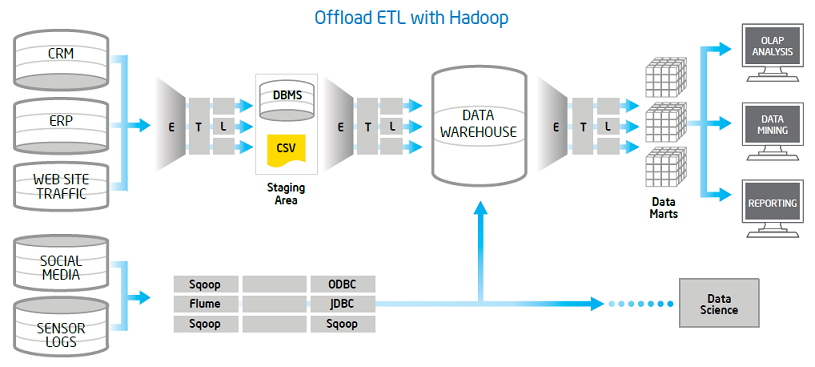
در قلب این چالش، فرایندیست که دادهها را از منابع مختلف استخراج مینماید، آنها را به نیازهای تحلیلی شما تبدیل نموده و در یک انبار داده برای تجزیه و تحلیل بعدی بارگذاری می نماید. اصطلاحا به این کار فرآیند “استخراج، تبدیل و بارگذاری” یا به اختصار (ETL) می گویند.
ماهیت داده های بزرگ نیازمند زیرساخت های فرآیند مقرون به صرفه میباشد. Apache Hadoop یک استاندارد واقعی برای مدیریت دادههای بزرگ میباشد. این مقاله به بررسی برخی از ملاحظات سخت افزاری و نرم افزاری در استفاده از Hadoop برای ETL می پردازد.
اتصال EDW و داده بزرگ
Apache Hadoop
Apache Hadoop یک پلت فرم نرم افزاری رایگان برای ذخیره و پردازش دادهها است.
به زبان جاوا نوشته شده و برروی یکی از کلاسترهای سرورهای استاندارد قرار گرفته است. با استفاده از Hadoop، میتوان با اطمینان، دادههای حجیم را بر روی دهها هزار سرور ذخیره کرد و در هزینه های خود صرفه جویی نمود.
Map Reduce
زبانهای برنامه نویسیای هستند که توسعه را با استفاده از چارچوب MapReduce ساده می کنند.
HiveQL دارای گواهی SQL است و از زیر مجموعه ی نحوی پشتیبانی میکند. با وجود اینکه آهسته است، Hive به طور فعال به کمک Apache HBase و HDFS فعال میشود. یک زبان رویهای است که انتصابهای سطح بالا را برای MapReduce فراهم میکند. شما میتوانید آن را با استفاده از توابع تعریف شده در جاوا، پایتون و دیگر زبان ها گسترش دهید.
Apache Hive
Apache Hive یکی از زبانهای برنامهنویسی است که توسعه برنامههای کاربردی را با استفاده از چارچوب MapReduce آسان میکند.
با وجود اینکه آهسته است، Hive به طور فعال توسط جامعه توسعه دهنده برای فعال کردن نمایش داده شده با زمان پایین در Apache HBase و HDFS فعال میشود. Pig Latin یک زبان برنامهنویسی رویه است که انتصابهای سطح بالا را برای MapReduce فراهم میکند.
شما میتوانید آن را با استفاده از توابع تعریف شده توسط کاربر نوشته شده در جاوا، پایتون و دیگر زبانها گسترش دهید.
Apache Flume
Apache Flume یک سیستم توزیع شده برای جمعآوری و انتقال دادههای بزرگ از منابع مختلف به HDFS یا یکی دیگر از فروشگاههای داده مرکزی است.
سازمانها معمولا فایلهای log را در سرورهای برنامه یا سایر سیستمها جمعآوری میکنند و فایلهای log را آرشیو میکنند تا مطابق با مقررات باشند.
فلوم قادر به گرفتن و تجزیه و تحلیل اطلاعات غیر ساختار یافته یا نیمه ساختاریافته در Hadoop است که میتواند ارزش آفرینی کند.